

Artificial intelligence (AI) can give your product a competitive edge. But to actually generate value with AI, you need high-quality AI training data.
To get that training data, start by deciding what you want to accomplish with your AI system. With this goal in mind, figure out what training data you need and how much. Then, finally, you can collect and prepare data to train your AI.
Decide what you want to achieve with your AI system
We should preface this by saying that AI isn’t the one and only solution to all problems. Oftentimes, there are much more effective and sophisticated technologies you can use.
Let’s imagine you want to keep readers on your website longer, for instance. There’s more than one way to do this, and not all of them require building a custom artificial intelligence engine.
- One approach would be to focus on reducing your blog’s bounce rate. You can achieve this through a variety of methods, including changing the page design, adding new sharing features, and creating better content.
- However, if you choose to captivate readers with the content most relevant to them, building an AI-powered content recommendation system would, in fact, be your best choice.

By setting a clear goal early on, you’ll accomplish two things: 1) make sure that AI is what you actually need, and 2) simplify the process of selecting, collecting, and preparing training data for it.

A bespoke AI can help you predict and forecast values, detect abnormal behaviors, find patterns, analyze impacts, and structure or classify data.
Value prediction
With regression analysis, you can predict what will happen in the future under certain conditions. Regression is a great statistical approach that helps you analyze connections between several variables to see how they influence each other.
For instance, regression analysis can help you predict how many sales you’ll generate next year by analyzing what has affected your sales in the past. In a similar manner, you can use regression analysis to estimate fluctuations in demand, income, customer satisfaction, etc.
Value forecasting
Use value forecasting to figure out what will happen within a certain timeframe. By analyzing past events, a value forecasting AI can help you project how the situation will develop within a given period of time.
Some practical implementations of this approach include estimating future sales figures, calculating when you’ll start generating a return on investments, and figuring out when to expect the highest growth in demand throughout the year.
Anomaly detection
You can notice abnormal situations and behaviors with anomaly detection. An anomaly detection AI analyzes data from the past to learn what’s considered a normal behavior and then looks out for anything that doesn’t fit that norm.
With anomaly detection, you can prevent customer fraud, build smart security systems, analyze readings from medical sensors, maintain stability in industrial settings, and so on.
Impact analysis
Impact analysis can help you decide what factors have the most influence on the results. It’s likely there are a limited number of factors driving your sales, and impact analysis can help you pin them down.
Other practical implementations of this approach include figuring out what content drives the most traffic and conversions and what can be detrimental to customer satisfaction in your industry.
Association
With the association approach, you can find patterns in various event sequences. For instance, you could have the AI analyze what items customers are likely to buy together, then suggest these items to other potential customers.
In industrial settings, the association approach can help you retroactively track changes in sensor readings before a system crash to avoid similar crashes in the future. You can also take note of how customers behave during checkout to find similarities between those customers who proceed with payment and those who abandon their carts.
See how Lemberg built a data science-enabled device for personnel hygiene control.
Clustering
AI makes it easy to structure data into categories based on similarities through clustering. This approach is great for when you want to make sense of whatever data you have.
Some examples of clustering are carving out target audiences, analyzing differences and similarities in the services provided by your competitors, and building account-based marketing strategies.
Classification
You can build an AI to answer simple and complex questions about data by implementing the classification approach.
Data classification can help you better understand your audience and customers: how happy they are about your services based on their tweets and comments, how likely they are to complete checkout, what you can do to provide them with a better experience, and so on.
Keep in mind that not all AI development starts with a desire to solve a certain industry problem. Sometimes, you just have a lot of data that you want to start generating value from, and that’s fine too. Regardless of what you’re starting with, make an effort to narrow down your end goal as much as possible.
Use your goal to decide what AI training data you need
To train an AI in solving the problem or achieving the goal you’ve identified, you need to give it enough data that is pertinent to that goal or problem. This data will constitute your training dataset.
Depending on the task, you’ll either need to supervise the AI learning process or let the AI teach itself.
- With supervised learning, you’ll need to feed the AI labeled data, telling the AI what inputs should result in what outputs. This approach is great when you already know what results you want the AI to produce (classification, anomaly detection, etc.).
- Unsupervised learning, however, means that the AI will analyze data and then decide what outputs to produce all on its own. You should implement this approach if you’re not sure what to expect from the data you have (clustering, value forecasting, and prediction, etc.)
When developing BarHelper, a computer vision-enabled AI that recognizes bottled and canned drinks and calculates the total cost of an order, we had to train the AI to:
- Identify specific cans and bottles in images and videos, and
- Figure out each drink’s name and price.
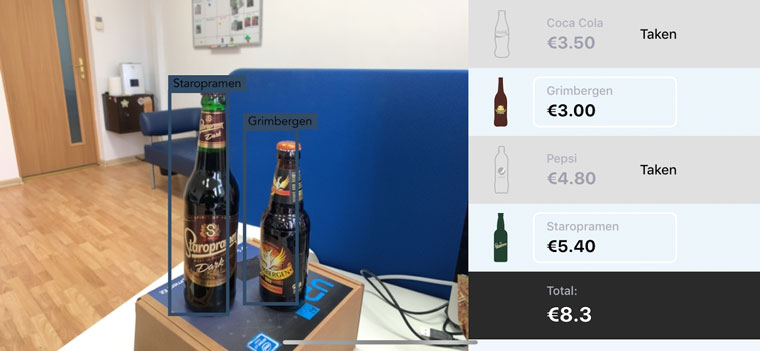
The BarHelper AI learned under supervision to provide the results we expected. To achieve this, our engineers selected several bottled drinks and took up to a thousand pictures of each from different angles.

This is roughly what you should do, too. Identify a goal, then consider what data can help you achieve that goal. It’s important, however, that you train your AI only on meaningful data. You won’t be able to teach any AI to recognize Coke cans by providing it with images of cars with cans hidden somewhere inside.
Take it from Pavlo Tkachenko, the head data scientist at Lemberg: “To train an AI in producing the results you expect, you should give it training data that has an explicit, meaningful connection to those results. You should never expect artificial intelligence to make the connections you yourself cannot make.”
Not only do you need relevant training data, but you also need a lot of it. But how much training data is enough to start developing an AI?
Estimate how much training data you need to get started
A good rule of thumb is the more high-quality training data you have, the better the AI you can develop. However, if you want to be a bit more precise, look at how complex your solution is going to be and how accurate you’re going to need it to be.
For example, when developing a wind turbine anomaly detection system, Pavlo Tkachenko had to create a solution that would detect any abnormalities in system behavior quickly and with extreme accuracy. Given the overall complexity of wind turbines and the AI requirements, Pavlo needed at least one year’s worth of wind turbine sensor readings consistently recorded at five- to ten-minute intervals.
This amount of data was just enough to teach the AI what normal wind turbine performance looks like throughout the year under different weather conditions. Once the AI learned about normal performance, it was able to accurately detect abnormalities in system behavior as far as two days in advance.
Reasoning by analogy, you should prepare enough training data to fully encompass your expectations for the AI. To help you arrive at the right conclusion, we suggest that you:
- Talk to industry experts
- Consider how complex the AI is going to be
- Decide how accurate you need the AI to be
- Always get more data, if you can

Talk to industry experts
The more you know about the area in which you’re developing an AI solution, the more likely you are to create a worthwhile product. Even if you think you know everything, still consider getting as many opinions as you can from industry experts. Each new input can help you come up with just a slightly better solution, and even the thinnest advantage can put you high above the competition.
Industry experts can help you see connections between data you might not have noticed before. This will help you figure out what training data can be the most useful, and maybe cause you to consider using data you hadn’t considered using before.

Consider how complex the AI is going to be
Remember that all artificial intelligence does is match inputs to outputs. It does so in creative ways and can hold many inputs and outputs at once, but that’s essentially all it does. The quantity of inputs your AI needs defines its complexity. Typically, you’ll need at least ten times as many data samples as there are inputs.
For instance, to build a smart content recommendation system, you would need to analyze your readers’ behavior, which you can do by collecting data about readers. Let’s say you’re going to collect five data points: age, gender, country of residence, and most and least viewed article tags. These will all be inputs to your AI. So to analyze users by these five data points, you’ll need to collect data from at least 50 people. The more inputs you’re going to analyze, the more training data you’ll need.
Decide how accurate you need the AI to be
You might have various degrees of error tolerance depending on the system you’re building. While it’s always desirable to make as accurate of a system as possible, medical monitors will arguably be a lot less tolerant of mistakes than, say, smart advertising campaigns.
Decide on the degree of error tolerance you’re going to allow and work from that. The more accurate you want the AI to be, the more training data you’re going to need.
Always get more data
If you have a clear goal and consistently collect meaningful data, always try to collect more. The if exists because the quality of data does often mean more than its quantity. However, with AI development, we’re always going to return to the first rule: the more high-quality data you have, the better your AI can be.
It is, therefore, important to establish effective data collection and preparation processes as early as you can.
Learn more: Getting Started with an Activity Tracking App. Data Collection for a Machine Learning Algorithm
Establish consistent data collection and preparation processes
Having decided on the goal, selected training data for collection, and estimated how much data you need to get started, you can proceed to actually collect and prepare training data for your AI.
Your process for collecting training data will vary depending on the goal you’ve set out to achieve. It might consist of summarizing sales data, surveying customers and users, collecting sensor readings, etc. The only real advice at this stage is to keep data collection consistent.
Each new training dataset has to have the same inputs as the previous one. If your first dataset contains columns with age, gender, and the native language of your users, your next datasets should also contain the same columns — no more, no less. You shouldn’t have one training dataset with age, gender, and native language, another with age and gender, and a third with age only. The AI won’t be able to make sense of training data if it’s inconsistent.
We say should and shouldn’t because inconsistencies aren’t going to make or break the AI at the data collection stage. There are always ways to perfect the data later on, but you really don’t want to waste time cleaning and formatting data if you’re able to collect consistent data from the start.
To collect training data for BarHelper, our engineers took pictures of several bottles. However, the photos alone weren’t sufficient to train the AI.
We remedied the situation by building an image distortion algorithm. It twists, stretches, resizes, blurs, and by other means distorts bottle images to replicate how different cameras might view bottles under various circumstances. This helped us bring the necessary volume and variety to the training dataset.
This is what data preparation is about: you take whatever data you have and apply various techniques to make it perfect for your AI. You can either focus on adding more data to the dataset, as we did with BarHelper, or reducing the amount of data to ensure its quality and consistency – or performing both as necessary.

Clean the data of missing values
Missing values will drastically reduce the accuracy of your AI. You can fix missing values by substituting them with dummy values or averages. In case it’s impossible to fill in the missing rows and columns, you could also consider removing them altogether: It’s better to have less clean data than to have a lot of dirty data.
Format data for consistency
If your dataset aggregates data from different sources, or if different people were responsible for updating it at different times, ensure record consistency. For instance, all the dates have to follow the same format, all addresses should be filled out the same way, all monetary values should follow the same style, etc.
Make the units consistent
It’s important to use consistent units, as this will improve the speed and accuracy of the AI. There shouldn’t be values in kilograms and pounds at the same time or different currencies all mixed together. Put all values of the same type in the same units: convert all weights to kilograms, all currencies to dollars, and so on.
Decompose complex values
Sometimes, you’re going to collect compound values, and the AI will be able to make sense of them. However, there are also cases where you need to split complex values into simpler ones for faster and more accurate processing: breaking down months into days, separating large comments into keywords, etc.
Aggregate simple values
Alternatively, sometimes having small and specific values can hinder AI efficiency. To remedy that, combine smaller data points into larger ones: group users not by precise ages but by age ranges; collect not singular sensor readings but calculate average values for a given day or week, and so on.
This list of data preparation techniques is far from exhaustive. Depending on the task, data engineers can choose to transform data in a variety of ways, ensuring the highest accuracy and efficiency they can possibly get from the AI.
Partner with Lemberg to develop a better AI
Developing a full-fledged artificial intelligence system is a complex process that requires a lot of preparation.
Your first step should always be establishing exactly what you want to achieve. A clear goal will help you decide what data you need to collect and estimate how much data you need to get started. Then you still need to get down to the nitty-gritty of collecting and preparing data — a grueling process for someone with little practical experience in data science and engineering.
That’s why we recommend our data science development services to help you develop the best AI possible. Learn more about machine learning and AI projects we’ve developed at Lemberg. Our expertise covers a variety of industries, and we have even more AI and machine learning projects currently in the works. Write us a quick note to learn how Lemberg can help you develop an outstanding artificial intelligence system.


